WiSE Webクローラ
クローリングの対象範囲や処理の並列度などを自由に指定
WiSE Webクローラは、BSTが自社開発したWebクローラです。全文検索エンジンWiSEのオプションとして、また単独でご利用いただけます。
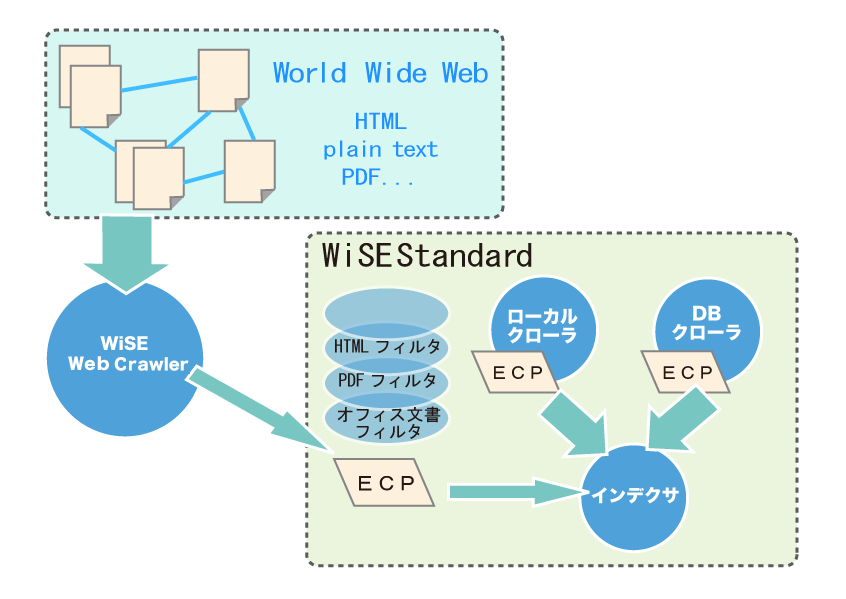
WiSE Webクローラは、指定されたURLからハイパーリンクをたどってデータファイルを収集します。
WiSE Webクローラは次のような特長を備えています。
WiSE Webクローラは、クローリングの対象範囲や処理の並列度などを自由に指定できます。
また、異なる多数のドメインのクローリングを並列で高速に実行できます。
収集先のWebサーバへの負荷を考慮する場合、1 URL の取得後に次のリクエストを開始するまでの間隔も指定できます。
WiSE Webクローラは、各URLが「取得済」か、そもそも「収集対象」か? などの判定に独自の収集条件データベース (WCDB) を使用します。このデータを元に、変更のない文書は取得しないようにクローリングを行います。
収集ドメイン(Webサーバ名)、URL、ファイル形式などを柔軟に指定できます。
正規表現にマッチしたURLの収集や除外、PDFファイルの収集なども可能です。
さらに、1回のクローリングで取得するURL数や、ファイルサイズの合計、巨大なファイルの除外など、多彩なオプションでクローリング対象を指定できます。
HTMLの特定のタグに囲まれたテキストを取り出すことができます。ヘッダやフッタなどの共通部分を取り除き、本文のみを収集できます。
クローリングを開始するURLを複数指定できます。クローリングを開始するURLを深さ0(ゼロ)として、その文書から張られたリンクを1とカウントする方法で、指定された深さ(リンクの隔たり)までクローリングします。また、sitemap.xmlにも対応しています。
クローリングの範囲や、時間、ファイル数などをきめ細かく制御できます。クローリングの範囲は、ドメインや、パス、アンカーテキスト、URLのパターンによって制限することが可能です。
クローリングを途中で中断しても、WCDBの収集履歴を元に、中断したクローリングを再開できます。サーバへの負荷が高まる時間帯を避けたり、一度で収集しづらい大規模サイトを複数回に分割して収集したりできます。
WiSE Webクローラは、WiSEとのセット、または単独でご購入いただけます。